
Основы машинного обучения в контекстной рекламе
Машинное обучение (ML) представляет собой раздел искусственного интеллекта, в котором компьютерные системы обучаются автоматически улучшать свои действия на основе анализа данных. В контекстной рекламе ML используется для более точного прогнозирования и оптимизации рекламных кампаний. Алгоритмы машинного обучения анализируют огромные объемы данных, такие как поведение пользователей, истории кликов и предыдущие результаты рекламных кампаний, чтобы определить наилучшие стратегии таргетинга.
Использование машинного обучения в контекстной рекламе позволяет адаптировать показы рекламы в реальном времени. Это означает, что алгоритмы могут быстро корректировать рекламные ставки и выбрать наиболее релевантные аудитории для показа объявлений. Например, алгоритмы могут предсказать, какое объявление с большей вероятностью приведет к конверсии для конкретного пользователя, основываясь на его предыдущих действиях и предпочтениях.
Эффективность машинного обучения в контекстной рекламе также связана с его способностью учитывать множество факторов одновременно, таких как время суток, тип устройства, географическое положение и даже погода. Это делает рекламные кампании более персонализированными и, следовательно, более эффективными. Рекламодатели могут получать более высокий возврат на инвестиции, так как алгоритмы помогают сократить расходы на нерелевантные показы и увеличить количество конверсий.
Машинное обучение становится неотъемлемой частью контекстной рекламы, так как оно позволяет автоматизировать многие процессы, которые ранее требовали ручного вмешательства. Это снижает человеческий фактор в принятии решений и минимизирует ошибки, что особенно важно для крупных рекламных кампаний с большими бюджетами.
Историческое развитие методов предсказания конверсий
Методы предсказания конверсий развивались параллельно с развитием маркетинга и аналитики. В начале компании полагались на интуицию и опыт, чтобы оценить, как те или иные рекламные усилия повлияют на конверсии. Статистические методы, такие как линейная регрессия, стали первыми инструментами, которые позволили более точно прогнозировать результаты. Эти методы основывались на анализе исторических данных, что позволяло выявлять корреляции между различными маркетинговыми действиями и результатами. Однако такие подходы имели ограниченные возможности: они не могли учитывать сложные взаимосвязи между множеством факторов, влияющих на конверсии.
С развитием технологий и появлением цифровых платформ маркетологи начали использовать более сложные алгоритмы и инструменты, такие как логистическая регрессия и байесовские методы. Эти методы позволили учитывать нелинейные зависимости и включать большее количество переменных в анализ. Несмотря на это, точность предсказаний оставалась ограниченной из-за сложности маркетинговых процессов и поведения потребителей.
Появление машинного обучения стало прорывом в предсказании конверсий. Алгоритмы на основе машинного обучения, такие как деревья решений, случайные леса и нейронные сети, смогли значительно улучшить точность прогнозов. Эти методы учитывают огромное количество факторов и выявляют скрытые паттерны, которые не очевидны для традиционных статистических моделей. Важным преимуществом машинного обучения стало его способность адаптироваться к новым данным и изменяющимся условиям рынка, что делает прогнозы более релевантными и точными.
Таким образом, эволюция методов предсказания конверсий прошла путь от простых статистических моделей до использования передовых алгоритмов машинного обучения, что позволило значительно повысить точность и эффективность маркетинговых кампаний.
Алгоритмы машинного обучения: основные типы и их применение в рекламе
Алгоритмы машинного обучения предоставляют маркетологам инструменты для более точного прогнозирования и оптимизации конверсий. Правильное применение этих алгоритмов позволяет не только улучшить результаты рекламных кампаний, но и существенно сократить затраты. Рассмотрим основные типы алгоритмов ML и как они применяются в рекламе.
Линейная регрессия используется для анализа зависимости между одной зависимой и одной или несколькими независимыми переменными. Этот алгоритм часто применяется для предсказания стоимости конверсии на основе данных о предыдущих рекламных кампаниях. Прогнозы линейной регрессии позволяют оценить, какой бюджет потребуется для достижения определенного количества конверсий.
Деревья решений помогают структурировать данные в форме дерева, где каждый узел представляет выбор между разными вариантами на основе определенного признака. В контексте рекламы деревья решений полезны для сегментации аудитории и определения наилучших путей к конверсии, включая анализ факторов, влияющих на поведение пользователей.
Нейронные сети представляют собой сложные алгоритмы, состоящие из множества слоев, каждый из которых обрабатывает данные на разных уровнях абстракции. Эти алгоритмы применяются для более точного прогнозирования конверсий, особенно в условиях, когда данные неоднородны и содержат большое количество факторов. Нейронные сети могут выявлять скрытые зависимости в пользовательском поведении, помогая улучшить таргетинг рекламы.

Случайный лес (Random Forest). Это ансамблевый метод, основанный на множестве деревьев решений. Он снижает вероятность ошибок и повышает точность предсказаний за счет объединения результатов различных моделей. В рекламе случайный лес используется для оценки вероятности конверсии на основе большого количества входных данных, таких как демографические характеристики, поведенческие данные и предыдущие действия пользователей.

Методы опорных векторов (SVM) . Алгоритм этих методов используется для классификации и регрессии. В рекламе его применяют для разделения пользователей на группы с высокой и низкой вероятностью конверсии. Это позволяет оптимизировать рекламные кампании, фокусируя усилия на наиболее перспективных сегментах аудитории.

Кластеризация (K-means). Алгоритм кластеризации используется для группировки данных в кластеры на основе схожих признаков. В рекламе кластеризация помогает разделить аудиторию на сегменты с общими характеристиками, что позволяет создавать более персонализированные рекламные предложения и улучшать взаимодействие с пользователями.
Градиентный бустинг представляет собой алгоритм ансамбля, где новые модели обучаются исправлять ошибки предыдущих. Этот метод активно применяется для точного прогнозирования конверсий в условиях большого объема данных и высокой вариативности показателей. Градиентный бустинг помогает улучшить эффективность рекламы, корректируя стратегию на основе изменяющихся данных.
Особенности работы с большими данными
Большие данные предоставляют широкие возможности для анализа огромных объемов информации, что позволяет моделям машинного обучения обнаруживать скрытые закономерности и корреляции. Эти данные, собранные из различных источников, включают информацию о поведении пользователей, демографические характеристики, данные о транзакциях и многое другое. Чем больше данных анализируется, тем выше вероятность точного предсказания, поскольку модель учитывает больше факторов, влияющих на конверсии.
Однако работа с большими данными сопряжена с определенными вызовами. Одним из таких вызовов является необходимость обработки огромных массивов информации, что требует значительных вычислительных мощностей и эффективных алгоритмов. Без должного анализа и обработки, данные могут стать «шумом», затрудняющим извлечение полезных инсайтов. Важно не только собирать данные, но и уметь правильно их очищать и структурировать, чтобы избежать искажений в результатах предсказаний.
Кроме того, большие данные позволяют моделям машинного обучения постоянно адаптироваться к изменениям в поведении пользователей. Это делает предсказания более динамичными и актуальными, особенно в условиях изменяющихся рынков. За счет обработки и анализа таких данных, модели могут более точно определять, какие факторы оказывают наибольшее влияние на конверсии, и соответственно корректировать свои предсказания.
Таким образом, большие данные играют критическую роль в повышении точности предсказаний конверсий с использованием машинного обучения. Без правильного подхода к работе с этими данными, качество предсказаний значительно снижается, что может негативно сказаться на эффективности маркетинговых стратегий.
Хотите оставаться на шаг впереди в мобильной веб-разработке? В статье «Будущее адаптивного дизайна: как готовиться к новым трендам в мобильной веб-разработке» вы узнаете, какие изменения ждут адаптивный дизайн и как подготовить свои проекты к новым стандартам мобильного интернета!
Как машинное обучение улучшает точность предсказаний
Основная сила ML заключается в способности обрабатывать большие объемы данных и выявлять закономерности, которые остаются скрытыми для традиционных методов. Например, методы регрессии или линейного анализа опираются на предположение о линейной зависимости между переменными, что ограничивает их применимость в условиях, где взаимосвязи носят нелинейный характер. Машинное обучение, в отличие от этого, способно моделировать сложные нелинейные зависимости, что позволяет получить более точные прогнозы.
Применение алгоритмов машинного обучения, таких как градиентный бустинг или нейронные сети, значительно повышает качество предсказаний в задачах прогнозирования спроса, анализа поведения клиентов или оценки вероятности конверсии. Например, в рекламных кампаниях использование машинного обучения позволяет учитывать множественные факторы, включая исторические данные, поведение пользователей на сайте и внешние события. Это позволяет строить модели, которые более точно предсказывают вероятность совершения покупки, что в итоге приводит к оптимизации бюджетов и повышению эффективности рекламных затрат.
Ключевое преимущество машинного обучения заключается в его способности обучаться на новых данных, что позволяет моделям улучшаться со временем. Это особенно важно в условиях быстро меняющейся рыночной среды, где традиционные методы не способны оперативно реагировать на изменения. В отличие от фиксированных моделей, алгоритмы машинного обучения могут адаптироваться к новым условиям, предоставляя более актуальные и точные прогнозы.
Роль признаков в модели машинного обучения
Признаки в модели машинного обучения играют критическую роль в процессе предсказания конверсий. Ключевая задача специалиста по машинному обучению заключается в правильном выделении и выборе тех признаков, которые непосредственно влияют на результаты модели. Это процесс, требующий глубокого анализа и понимания данных, так как от него зависит точность и эффективность предсказаний.
Признаки представляют собой различные атрибуты или переменные, на основе которых алгоритм принимает решения. В контексте предсказания конверсий это могут быть такие параметры, как поведение пользователя на сайте, время на странице, источник трафика, исторические данные о покупках и многие другие. Процесс выделения признаков начинается с анализа имеющихся данных и определения тех переменных, которые могут иметь прямое или косвенное влияние на целевое действие пользователя.
Качество признаков влияет на способность модели различать успешные и неуспешные конверсии. Если признаки выбраны неправильно или их недостаточно, модель может давать неточные предсказания, что в конечном итоге снизит эффективность рекламных кампаний. Поэтому важно не только выбрать правильные признаки, но и правильно их обработать, устранить шум и аномалии, которые могут искажать результаты.
Процесс выделения признаков включает в себя как автоматические методы, такие как алгоритмы отбора признаков, так и экспертный анализ. Специалист должен учитывать не только текущие данные, но и возможность изменения поведения пользователей со временем. Это требует гибкого подхода и постоянного обновления модели в соответствии с новыми данными. Только такой комплексный подход позволит создать модель, которая будет точно предсказывать конверсии и помогать в оптимизации рекламных стратегий.
Интересуетесь, как использовать инновации для улучшения рекламных кампаний? В статье «Алгоритмы прогнозирования в таргетированной рекламе: Технологии завтрашнего дня» вы узнаете, как предсказательные алгоритмы меняют правила игры и помогают таргетировать аудиторию с высокой точностью!
Обучение моделей и выбор гиперпараметров
Обучение моделей машинного обучения основывается на процессе, который включает оптимизацию параметров и выбор подходящих гиперпараметров. В отличие от параметров, которые обновляются в ходе обучения модели, гиперпараметры устанавливаются до начала процесса и оказывают значительное влияние на конечные результаты. Например, в задачах классификации гиперпараметры могут включать количество слоев нейронной сети, размер мини-батчей, коэффициент регуляризации и скорость обучения.
Одной из ключевых задач является выбор оптимальных гиперпараметров, что требует тщательного подбора и тестирования различных их комбинаций. Методика поиска по сетке (grid search) предполагает перебор всех возможных значений гиперпараметров, но этот подход может быть ресурсоемким.

Альтернативой является случайный поиск (random search), который снижает вычислительные затраты, выбирая случайные комбинации гиперпараметров.
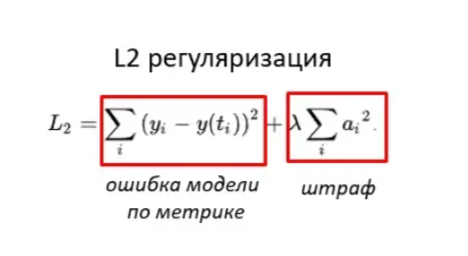
Еще одним важным аспектом обучения моделей является предотвращение переобучения. Для этого широко применяются техники регуляризации, такие как L2-регуляризация, которая добавляет штраф за сложные модели, уменьшая вероятность того, что модель будет чрезмерно приспосабливаться к данным. Правильная настройка гиперпараметров регуляризации может значительно повысить обобщающую способность модели.
Настройка скорости обучения также играет критическую роль в процессе обучения. Низкая скорость обучения может замедлить обучение модели, делая процесс неэффективным, тогда как слишком высокая скорость может привести к нестабильности обучения и невозможности достижения глобального минимума функции потерь. Оптимизация скорости обучения может быть выполнена с использованием методов адаптивной скорости обучения, таких как Adam или RMSprop.
Использование техники кросс-валидации позволяет более точно оценить качество модели на новых данных. В процессе кросс-валидации данные делятся на несколько подмножеств, и модель обучается на одном подмножестве, а проверяется на других. Это позволяет выявить наиболее удачные комбинации гиперпараметров, минимизируя риск переобучения и улучшая способность модели обобщать.
В целом, процесс обучения моделей и выбора гиперпараметров требует сбалансированного подхода, учитывающего все аспекты, от структуры модели до методов регуляризации и настройки гиперпараметров. Этот этап критичен для достижения высоких показателей точности и устойчивости модели в условиях реальных данных.
Применение кластеризации для улучшения предсказаний
Кластеризация пользователей является мощным инструментом для повышения точности предсказаний конверсий. Этот метод позволяет сегментировать аудиторию на группы с схожими характеристиками и поведением, что делает возможным более точное прогнозирование их будущих действий. В отличие от традиционных подходов, основанных на усреднённых данных по всей аудитории, кластеризация учитывает индивидуальные особенности каждой группы. Это значительно повышает точность предсказаний, так как учитываются более детализированные и релевантные данные.
Например, пользователи, которые активно взаимодействуют с рекламными материалами, но редко совершают покупки, могут быть выделены в отдельный кластер. Такой подход позволяет выявить скрытые закономерности в поведении и предложить им более подходящие маркетинговые стратегии. В свою очередь, это повышает вероятность конверсии, так как каждый кластер получает персонализированные предложения, соответствующие их интересам и потребностям.
Применение кластеризации также способствует более эффективному распределению рекламного бюджета. Фокусируясь на кластерах с высоким потенциалом конверсии, маркетологи могут значительно сократить затраты на рекламу, одновременно увеличивая доходы. Таким образом, кластеризация становится неотъемлемой частью стратегий предсказания конверсий, позволяя достигать более высоких показателей точности и эффективности в маркетинговых кампаниях.
Проблемы и вызовы машинного обучения в контекстной рекламе
Использование машинного обучения в контекстной рекламе открывает перед маркетологами новые возможности, однако процесс внедрения и применения этих технологий сталкивается с рядом существенных проблем. Одна из ключевых сложностей заключается в необходимости обеспечения качества исходных данных. Машинное обучение требует больших объемов информации для построения точных моделей предсказания конверсий, и любые ошибки, неточности или неполнота данных могут существенно снизить эффективность алгоритмов. Например, недостаточная сегментация аудитории или неучтенные сезонные колебания спроса могут привести к искажению результатов, что затрудняет правильное распределение рекламных бюджетов.
Еще одной значимой проблемой является интерпретируемость моделей машинного обучения. В большинстве случаев алгоритмы функционируют как «черный ящик», что затрудняет объяснение, почему были приняты те или иные решения. Это особенно критично, когда речь идет о принятии важных стратегических решений на основе рекомендаций алгоритмов. Маркетологи, которые не имеют глубоких технических знаний, могут испытывать затруднения в понимании и интерпретации результатов, что создает риски для неправильного использования данных в кампании.
Также значительные трудности возникают при адаптации моделей машинного обучения к изменениям в поведении пользователей и рыночных условиях. Алгоритмы, которые показывали высокую точность на момент обучения, могут терять актуальность, когда меняются предпочтения потребителей или появляются новые конкуренты. Это требует постоянного мониторинга и обновления моделей, что может оказаться трудоемким и затратным процессом для маркетинговых команд.
Кроме того, необходимо учитывать вопросы этики и конфиденциальности данных. В условиях ужесточения законодательства и роста осведомленности пользователей о защите личной информации, использование алгоритмов, которые анализируют большое количество персональных данных, требует особого внимания. Нарушение норм конфиденциальности или несанкционированное использование данных может не только подорвать доверие клиентов, но и привести к юридическим последствиям для компаний.
Этические аспекты применения машинного обучения
Машинное обучение активно используется для обработки и анализа пользовательских данных, что поднимает ряд важных этических вопросов. Один из ключевых аспектов заключается в конфиденциальности данных. Алгоритмы машинного обучения требуют больших объемов данных для обучения, что часто включает в себя сбор и анализ персональной информации. Это создает риск нарушения конфиденциальности пользователей, особенно если данные используются без их явного согласия или понимания того, как именно они будут обработаны.
Существуют также вопросы прозрачности алгоритмов. Многие модели машинного обучения работают как «черные ящики», что затрудняет понимание того, как именно принимаются решения на основе данных. Это может приводить к ситуациям, когда пользователи подвергаются дискриминации или иным несправедливым воздействиям без возможности оспорить результаты или понять, как они были получены.
Ответственность за принятые алгоритмами решения — еще один важный этический вопрос. В случае ошибок или необъективных решений, которые могут негативно повлиять на пользователей, возникает вопрос о том, кто несет ответственность: разработчики, компании, использующие алгоритмы, или сами алгоритмы? Отсутствие четкого ответа на этот вопрос усложняет внедрение машинного обучения в чувствительные области, такие как здравоохранение или правосудие.
Внедрение машинного обучения также может усилить социальное неравенство. Если алгоритмы обучаются на данных, которые уже содержат элементы дискриминации, они могут неосознанно усилить существующие предрассудки и стереотипы. Это требует внимательного подхода к подбору и очистке данных, а также регулярного мониторинга работы алгоритмов на предмет выявления возможных отклонений.
Эти вопросы подчеркивают необходимость разработки четких этических норм и стандартов для применения машинного обучения. Компании, работающие с этими технологиями, должны уделять особое внимание защите прав пользователей, обеспечивая прозрачность своих алгоритмов и принимая меры для минимизации потенциального вреда.
Примеры успешного внедрения машинного обучения в контекстную рекламу
Машинное обучение активно внедряется в контекстную рекламу и уже привело к значительным изменениям в результатах компаний, которые смогли использовать его потенциал. Например, компания «Google» внедрила алгоритмы машинного обучения для улучшения эффективности рекламных кампаний через платформу Google Ads. Система Smart Bidding анализирует огромные объемы данных и автоматически корректирует ставки, чтобы оптимизировать конверсии в реальном времени. Один из ярких кейсов связан с компанией «L’Oréal», которая использовала Smart Bidding для продвижения своих косметических продуктов. В результате они смогли увеличить количество конверсий на 20% при том же уровне затрат, что существенно улучшило рентабельность рекламных инвестиций.
Другой пример — платформа «Amazon», которая использует машинное обучение для персонализации рекламных предложений на основе поведения пользователей. Это позволило «Amazon» увеличить CTR (Click-Through Rate) своих рекламных кампаний, что напрямую отразилось на доходах компании от контекстной рекламы. Они применяют модели, которые учитывают не только предыдущие покупки и просмотры товаров, но и множество других факторов, таких как время суток, день недели и даже погодные условия. Эти данные обрабатываются в реальном времени, что делает рекламу более релевантной и привлекательной для пользователей.
Компании, работающие с программными инструментами типа «Criteo», также демонстрируют успешные примеры использования машинного обучения в контекстной рекламе. Их технологии позволяют предсказать вероятность конверсии для каждого пользователя и автоматически регулировать рекламные бюджеты. Это привело к увеличению коэффициента конверсии на 38% среди клиентов Criteo, что делает их одним из лидеров в области рекламных технологий, основанных на машинном обучении.

Эти примеры показывают, что правильное внедрение машинного обучения в контекстную рекламу может значительно повысить эффективность рекламных кампаний, увеличить рентабельность и предоставить пользователям более релевантные и персонализированные предложения.
Роль машинного обучения в автоматизации рекламных кампаний
Машинное обучение значительно изменило подход к управлению рекламными кампаниями, позволяя автоматизировать многие рутинные процессы и делать управление более эффективным. Одним из ключевых аспектов автоматизации является способность машинного обучения анализировать большие объемы данных в реальном времени. Алгоритмы могут обрабатывать информацию о поведении пользователей, их предпочтениях и конверсиях, чтобы на основе этих данных корректировать ставки, определять наиболее релевантные ключевые слова и адаптировать объявления под целевую аудиторию.
Еще одним важным аспектом автоматизации является прогнозирование результатов кампаний. Используя исторические данные, алгоритмы машинного обучения могут предсказывать, какие объявления и какие ключевые слова с большей вероятностью приведут к конверсиям. Это позволяет значительно снизить затраты на тестирование и оптимизацию, так как алгоритмы автоматически выбирают наилучшие варианты.
Автоматизация также касается настройки таргетинга и ретаргетинга. Алгоритмы машинного обучения могут автоматически определять наиболее перспективные сегменты аудитории и нацеливать на них рекламные кампании. Это позволяет более точно достигать нужной аудитории, минимизируя затраты на показы нерелевантным пользователям.
Кроме того, машинное обучение улучшает управление бюджетом рекламных кампаний. Алгоритмы могут автоматически перераспределять бюджет между разными кампаниями и каналами, основываясь на их эффективности в реальном времени. Это способствует более рациональному использованию ресурсов и достижению поставленных целей с минимальными затратами.
В результате, внедрение машинного обучения в управление контекстной рекламой позволяет значительно повысить эффективность рекламных кампаний, снизить затраты на их ведение и автоматизировать рутинные задачи, что освобождает время маркетологов для стратегического планирования и анализа.
Влияние качества данных на результаты предсказания
Когда исходные данные содержат ошибки, пропуски или нерелевантные элементы, это напрямую влияет на способность алгоритма правильно интерпретировать информацию и делать точные прогнозы. Полные и точные данные позволяют модели выявлять закономерности и тенденции, которые в противном случае могли бы остаться незамеченными. В процессе машинного обучения, даже незначительные отклонения в качестве данных могут привести к значительным ошибкам в предсказаниях. Например, если модель обучается на неполных данных, она может сформировать ложные зависимости, которые не отражают реальной картины.
С другой стороны, избыточные или шумные данные могут перегрузить модель, что приведет к снижению ее эффективности. Чем больше «шумов» в данных, тем сложнее модели выявлять истинные закономерности. Это может привести к переобучению, когда модель хорошо работает на обучающей выборке, но показывает низкие результаты на новых данных.
Точность предсказаний также зависит от разнообразия и репрезентативности данных. Если данные недостаточно разнообразны или охватывают лишь часть возможных сценариев, модель может плохо справляться с прогнозированием в новых условиях. Следовательно, для достижения высокой точности предсказаний необходимо уделять особое внимание процессу сбора и предварительной обработки данных, обеспечивая их полноту, точность и релевантность.
Интеграция машинного обучения в существующие системы аналитики
Анализ данных с помощью машинного обучения. Внедрение машинного обучения (ML) в аналитические системы требует анализа данных, собранных из различных источников, таких как CRM, системы управления контентом, платформы e-commerce и рекламные системы. Прежде всего, необходимо структурировать данные, нормализовать их и устранить дубли. Это обеспечит качественную подготовку для обучения моделей ML. Использование продвинутых алгоритмов машинного обучения позволяет выявлять скрытые закономерности и прогнозировать поведение пользователей на основе предыдущих действий, что значительно повышает точность предсказаний.
Интеграция с инструментами бизнес-аналитики. Чтобы интегрировать машинное обучение в существующие системы аналитики, необходимо использовать API или встроенные модули, которые поддерживают обработку данных в реальном времени. Популярные инструменты, такие как Google Analytics и Power BI, предлагают функциональные возможности для интеграции с ML моделями. Это позволяет автоматизировать процесс анализа и оперативно реагировать на изменения в поведении пользователей.
Оптимизация рабочих процессов. После интеграции машинного обучения в систему аналитики, важно автоматизировать рабочие процессы. Для этого необходимо установить правила, которые будут активировать запуск ML моделей при достижении определённых условий, например, при изменении ключевых показателей эффективности (KPI). Это снижает необходимость ручного вмешательства и позволяет системе автоматически адаптироваться к новым условиям рынка или поведения пользователей.
Мониторинг и обновление моделей. Интеграция машинного обучения требует постоянного мониторинга качества предсказаний и периодического обновления моделей на основе новых данных. Это включает регулярный пересмотр алгоритмов и корректировку параметров для поддержания точности и актуальности предсказаний. Системы аналитики должны быть настроены на автоматическое обновление моделей при появлении новых данных, что позволяет сохранять высокую точность прогнозов на протяжении всего жизненного цикла модели.
Такой подход позволяет не только повысить точность аналитики, но и улучшить предсказания, что в конечном итоге приводит к более эффективному управлению бизнесом и увеличению прибыли.
Будущее машинного обучения в контекстной рекламе
Машинное обучение уже существенно изменило контекстную рекламу, и его будущее обещает еще более значительные трансформации. Одной из ключевых перспектив развития является интеграция более сложных алгоритмов, которые способны анализировать и обрабатывать огромные объемы данных с еще большей точностью. Это позволит предсказывать поведение пользователей с минимальными погрешностями, улучшая таким образом эффективность рекламных кампаний.
Среди инноваций стоит выделить внедрение моделей глубокого обучения, которые могут не только учитывать текущие данные, но и адаптироваться к изменениям в реальном времени. Это открывает возможности для создания динамических кампаний, где реклама подстраивается под поведение пользователя на лету. Также развивается направление использования нейронных сетей для персонализации рекламных сообщений, что повышает вероятность конверсии.
Еще одной важной тенденцией становится усиление автоматизации процессов, связанных с управлением рекламными кампаниями. Системы машинного обучения смогут самостоятельно выбирать оптимальные ключевые слова, определять наиболее эффективные форматы рекламы и настраивать бюджеты с учетом текущих результатов. Это снижает человеческий фактор и позволяет более эффективно использовать ресурсы.
Таким образом, будущее машинного обучения в контекстной рекламе связано с дальнейшей оптимизацией процессов предсказания конверсий, использованием более продвинутых алгоритмов и повышением уровня автоматизации. Эти изменения уже начинают влиять на рынок, и в ближайшие годы можно ожидать еще более глубокого внедрения этих технологий.
- 18 мин
- 164
- 56